Collection-scoped MongoDB change streams
MongoDB pipelines can now opt intocollectionScopedMode for tighter isolation between collections. Artie opens an independent stream for each configured collection, polls streams round-robin, and stores a separate resume token for each one. Ordering is preserved within a collection, not across collections. The database-level stream remains the default; this mode requires sufficient maxConcurrentStreams capacity and a maxPoolSize greater than the number of active streams.Why this matters- Let a busy collection resume independently after a failure without affecting its neighbors
- Get per-collection ordering and recovery guarantees that a shared CDC stream cannot offer
Server-side filtering for MongoDB CDC
MongoDB database-wide change streams now apply configured database and collection filters before Artie decodes events, rather than relying only on a later client-side guard. The client-side check remains as a second layer.Why this matters- Cut unnecessary change-stream traffic for pipelines that watch only part of a database
- Preserve behavior for pipelines already relying on the existing client-side check
Postgres replication supports citext
Homogeneous PostgreSQL replication now recognizes the citext type during table introspection instead of rejecting it as unsupported. Artie preserves citext when generating destination schema changes, so case-insensitive text columns pass through merge DDL without being reduced to an incompatible type.Why this matters- Replicate tables with
citextcolumns without a schema-inspection failure - Keep the source’s native type on the destination rather than using a lossy substitute
Automatic schema reconciliation after redeploy
Pipelines with automatic schema changes enabled can now reconcile destination schemas after a successful, non-first redeploy. Artie schedules reconciliation only when the pipeline and data plane are not locked, rechecks the setting in the worker, and applies a four-hour per-pipeline cooldown shared with the scheduled job. The existing company setting still controls the behavior.Why this matters- Close the gap between a redeploy and the destination schema catching up to source changes
- Avoid duplicate reconciliation work when deploys land close together
MongoDB server details in the Data Catalog
MongoDB connector detail pages now show server settings in the Data Catalog metadata section. The Dashboard renders server version and other connector metadata on both cluster and database views.Why this matters- Check MongoDB source version and server details without leaving the Data Catalog
- Bring MongoDB in line with metadata views already available for other connectors
Global navigation, searchable with Command-K
The Dashboard now provides a shell-wide Command-K navigator for logged-in users, covering pages, settings, pipelines, and permission-gated admin results. Companies with the rollout flag enabled also get fuzzy matching, so a typo can still find the right destination.Why this matters- Jump between pipelines, settings, and other frequent destinations from one shortcut
- Keep admin results permission-gated while Hermes Diary and Catalog search behavior remain unchanged
More Contrast, a higher-contrast Dashboard theme
Artie 2.0 now includes a user-controlled More Contrast option under User Settings → Appearance. It strengthens text, borders, controls, statuses, and chart colors. It respects the systemprefers-contrast setting until a user makes an explicit choice; v1 and the default v2 presentation are unchanged.Why this matters- Sharpen distinction between controls, boundaries, statuses, and chart series for anyone who needs it
- Add an explicit override on top of the system-level contrast preference, not a replacement for it
Higher-throughput Snowpipe Streaming
Snowpipe Streaming can now fan rows across stable channels using the configured channel limit, drain those channels concurrently, and retain per-channel retry and commit behavior. Related Snowflake changes make pipe creation idempotent, keep retries deterministic, match pipe columns by name, and apply streaming to both history and replication modes.Why this matters- Increase Snowflake ingestion throughput for larger pipelines
- Preserve key ordering within a channel while using parallel writes
- Reduce duplicate or failed writes during retries and schema changes
Configurable table-change notification schedule
Company admins can now configure the weekdays, start time, and timezone for table-change notifications from Company settings. Other team members can view the effective schedule, and Artie validates changes and avoids duplicate checks when the schedule is edited.Why this matters- Receive schema-change notifications when your team is ready to act
- Avoid alerts during weekends or outside business hours
- Give admins a clear, human-readable view of the active schedule
MSSQL and Oracle replica ports for backfills
MSSQL and Oracle replica settings could override the replica host but not its port, forcing replicas to use the primary database’s port.Both connectors now accept an optionalsnapshotPort for backfills. When it is unset, Artie continues to use the primary port; streaming remains on the primary connection.Why this matters- Support replicas hosted on a different port from the primary database
- Route snapshot traffic to the correct MSSQL or Oracle replica endpoint
- Keep existing configurations unchanged by preserving the primary-port fallback
MongoDB and DocumentDB field controls
Teams replicating document databases often need to exclude sensitive fields or transform them before they leave the source.Artie now exposes advanced MongoDB and DocumentDB settings for field exclusion, hashing, and encryption, including sampled field suggestions while configuring a source. The settings are available through the pipeline configuration experience.Why this matters- Keep sensitive document fields out of replicated data
- Apply consistent hashing or encryption policies at the source
- Configure field-level controls without hand-editing pipeline internals
MySQL binary values
MySQLBINARY values were not consistently represented during replication, particularly for fixed-width binary columns.Artie now supports MySQL binary values and preserves the required zero-padding for BINARY(n) during streaming.Why this matters- Replicate MySQL schemas that use binary identifiers and fixed-width values
- Preserve the source representation instead of losing significant padding
MongoDB updates with large fields
MongoDB change-stream updates with very large fields could carry redundant update metadata, increasing the risk that an event would exceed BSON size limits before Artie decoded it.Artie now removes that redundantupdateDescription metadata from DML change-stream events while continuing to deliver the complete post-image for update-lookups. Existing full-document and client-side lookup behavior remains unchanged.Why this matters- Replicate MongoDB updates containing very large fields more reliably
- Reduce unnecessary event size on the change-stream path
- Preserve complete updated documents for existing lookup configurations
MongoDB network compression by default
MongoDB replication can transfer substantial volumes of data between the source and Artie, and connections without an explicit compression setting previously sent uncompressed traffic.Artie now enables MongoDB wire compression by default, preferring zstd and falling back to zlib when no compressor is specified in the connection URI. Explicitcompressors settings remain authoritative.Why this matters- Reduce network payload size for MongoDB replication
- Improve efficiency without requiring a configuration change
- Retain control over compression when a URI specifies a preferred compressor
Create a workspace from the access-request flow
Users who reach the existing-company path during signup can now create a separate workspace instead of only requesting access to the existing one. The form collects a workspace name and user details, creates the workspace through the token-gated signup flow, and signs the user in. The original request-access flow remains available for users who want to join the existing workspace.Why this matters- Give users a self-serve path when the existing workspace is not the right home, with no admin handoff required
- Preserve the original request-access flow for users who do want to join the existing workspace
PlanetScale (MySQL) source connector
PlanetScale users previously needed a separate setup path to bring their MySQL-compatible data into Artie.Artie now includes a PlanetScale (MySQL) source connector with connector-specific setup guidance, service-account instructions, and the TLS and default-port handling required for Vitess/VStream connections.Why this matters- Start replication from PlanetScale through the standard connector flow
- Follow source-specific setup guidance instead of adapting generic MySQL instructions
- Connect using PlanetScale’s gRPC/VStream requirements
Self-serve PrivateLink setup and recovery
PrivateLink provisioning could require manual intervention when a connection failed, and self-serve customers had limited visibility into the process.PrivateLink is now supported in the pipeline setup wizard for self-serve customers, with approval controls, customer-visible provisioning failures, and a retry action for errored connections. Artie also enforces self-serve connection limits and surfaces the applicable allowance before charging begins.Why this matters- Configure private connectivity as part of pipeline setup
- Recover from transient provisioning failures without starting over
- Understand limits and costs before adding additional connections
Oracle streaming through Artie Reader
Artie now supports generating Oracle Reader streaming configuration through an explicit engine setting, while preserving the existing connector configuration model.Why this matters- Choose the Oracle streaming engine that fits your deployment
- Use the Reader path for Oracle workloads that need it
Composite PostgreSQL types as text
PostgreSQL composite types can be difficult to map into destination schemas when downstream systems do not support the native type.PostgreSQL sources now support an opt-incompositeTypesAsText setting, also available as composite_types_as_text in Terraform, to represent composite values as text.Why this matters- Replicate PostgreSQL tables containing composite types into broader destination sets
- Choose a portable representation without changing the source schema
MSSQL fan-in controls
MSSQL deployments with multiple databases needed more control over how new tables were unified across databases.Artie now supports per-table opt-out and source-level controls for MSSQLunifyAcrossDatabases, along with database selection and backfill actions in the dashboard. New tables can inherit the configured behavior while individual tables retain an override.Why this matters- Consolidate compatible MSSQL databases without forcing every table into one shape
- Keep exceptions for tables that must remain separate
- Manage fan-in behavior and backfills from the pipeline UI
Replication flow controls
Stopping or pausing a pipeline previously required navigating through less direct controls, making it harder to manage table-level replication safely.Pipeline tables now expose Stream, Pause, and Stop controls, with replication status made more discoverable and bulk pause support. Backfill-aware status indicators and deployment prompts clarify how an action interacts with active backfills.Why this matters- Control replication at the table level
- Pause multiple tables during maintenance or investigation
- See whether a table is streaming, paused, or backfilling before acting
Customer-settable PostgreSQL connection idle timeout
A single default PostgreSQL connection-pool idle timeout did not fit every pipeline’s workload or database policy.Artie now allows the idle timeout to be configured at the pipeline level.Why this matters- Match connection behavior to PostgreSQL server and network policies
- Tune long-lived pipelines without changing global defaults
Kafka message compression
Compressed Kafka message values could not previously be consumed through Artie’s transfer path.Artie now supports decompressing gzip-compressed Kafka message values, with the source-reader configuration exposed through Terraform.Why this matters- Ingest Kafka topics that use gzip-compressed values
- Reduce transport volume without adding a custom preprocessing step
Guided pipeline setup wizard
Creating a pipeline required moving between connector configuration, table selection, validation, and deployment screens without a single guided flow.Artie now provides a multi-step setup wizard covering source credentials and configuration, connection methods, table selection, destination setup, connector-specific guidance, and a final review-and-deploy step. Existing connectors can be reused, and existing SSH tunnels can be selected for either side of a pipeline.Why this matters- Set up a pipeline through one guided sequence
- Validate source and destination configuration before deployment
- Reuse connectors and SSH tunnels instead of recreating them
DynamoDB backfill setup in the wizard
The setup wizard now includes a DynamoDB-specific backfill step with S3 export guidance, validation, and an explicit option to save or continue without validation.Why this matters- Configure DynamoDB export and backfill requirements during onboarding
- Catch source configuration issues before deployment
- Keep the backfill setup close to the source and table selections it affects
PostgreSQL destinations for self-serve
PostgreSQL is now available as a self-serve destination, with a dedicated setup guide and SQL instructions in the pipeline wizard.Why this matters- Use PostgreSQL destinations without a custom sales-assisted setup
- Follow destination-specific grants and configuration guidance
Backfill-aware pipeline status
During an initial backfill, elevated ingestion lag could look like a problem even though streaming was already active.The dashboard now explains when tables are queued or backfilling, shows table-level status chips, and surfaces a backfill indicator on pipeline lists and home. The UI intentionally provides status context without inventing progress percentages or ETAs.Why this matters- Distinguish expected backfill activity from an incident
- See which tables are queued, backfilling, or already streaming
- Reduce unnecessary investigation during initial setup
Magic-link login
Users who could not or did not want to use a password or SSO path needed another way to sign in.Artie now supports one-time, rate-limited magic-link authentication with dedicated request and completion pages, expiry and single-use token checks, and email delivery.Why this matters- Sign in without entering a password
- Use a secure, single-use link that cannot be replayed
- Get clearer handling for invalid or expired links
MotherDuck multi-step merge
Multi-step merge optimization was previously exposed only for Snowflake destinations.The optimization is now available for MotherDuck as well as Snowflake through the destination advanced settings.Why this matters- Use multi-step merge with MotherDuck destinations
- Improve merge workflows without changing the destination’s core setup
JSON Diff in Pipeline History
Reviewing pipeline changes should not require diffing large JSON blobs.Pipeline history now renders large JSON fields as structured JSON diffs so you can quickly see exactly what changed between versions. Instead of displaying two full JSON documents, Artie highlights only the modified keys and values.For example, if a pipeline’s advanced settings changetimeouts.merge from 7200 to 5400, the history view highlights that specific change rather than rendering the entire JSON configuration.Why this matters- Review configuration changes quickly during debugging and deployments
- Make modifications obvious without scanning large JSON blobs
- Reduce the risk of missing unintended configuration changes during audits or reviews
Webhook failure alerts and dashboard visibility
Webhook failures were previously silent — there was no way to know a downstream integration had stopped receiving events without actively checking.The dashboard now shows when a webhook is in a failing state, including how long it has been failing. When a webhook exhausts its retries and transitions to a failing state, Artie sends an email alert to your company’s alert recipients. A recovery email fires automatically once delivery resumes.Why this matters- Get notified immediately when webhook delivery fails — not hours later
- See failure duration directly in the dashboard without any manual investigation
- Know when integrations recover without polling or checking manually
Webhooks accessible to all team members
Previously, only company admins could view or manage webhook settings, which created unnecessary friction for engineers who needed to wire up or debug integrations.Webhook settings are now visible and manageable by any team member with edit permissions. View-only accounts can see the webhook list with secrets redacted.Why this matters- Engineers can set up and debug webhooks without waiting for an admin
- Reduces bottlenecks during integration setup and incident response
Skip backfill per table
For tables where historical data is already loaded externally, forcing an initial snapshot wastes time and compute.Tables can now be configured withskipBackfill: true to bypass the initial snapshot and go straight to streaming CDC. This is available in both the dashboard UI (under advanced table settings) and the Terraform provider.Why this matters- Skip unnecessary snapshots when history is already in place
- Speed up onboarding for tables that only need ongoing CDC
- Consistent control through both the dashboard and Terraform
MySQL schema fan-in across multiple databases
Multi-tenant MySQL setups often have one schema per customer (e.g.tenant_001.orders, tenant_002.orders). Previously this required a separate pipeline per schema.MySQL now supports unifyAcrossSchemas, which fans in tables matching a regex pattern across multiple databases into a single unified destination topic. This works for both snapshot and streaming (CDC) paths.Why this matters- Consolidate multi-tenant or sharded MySQL setups into a single pipeline
- Eliminate per-schema pipeline sprawl in fan-in architectures
- Works end-to-end — snapshot and streaming
Resumable DynamoDB snapshots
Large DynamoDB exports can take hours. If a snapshot was interrupted, the only option was to restart from scratch.DynamoDB snapshot config now accepts astartAfterKey — an S3 key to resume from — so interrupted snapshots can pick up where they left off without reprocessing completed files.Why this matters- Recover from interrupted snapshots without re-running the full export
- Practical for large DynamoDB tables where restarts are expensive
Oracle: spatial geometry columns now replicated as WKT
OracleSDO_GEOMETRY columns (spatial/GIS data) were previously unsupported, blocking pipelines on any table that used them. Separately, DATE/TIMESTAMP values with years outside the valid range [0, 9999] would crash the pipeline entirely.Oracle SDO_GEOMETRY columns are now replicated as WKT (Well-Known Text) strings. Out-of-range timestamps are filtered to null instead of causing errors.Why this matters- Unblocks Oracle pipelines on tables with spatial/GIS columns
- Prevents pipeline failures from legacy timestamps with out-of-range years
Oracle: index-driven backfills for tables without primary keys
Oracle tables that lack a primary key but have a unique index were falling back to full table scans during backfill, making snapshots extremely slow.WhenprimaryKeysOverride points to a unique index, Artie now injects an index hint into backfill queries to force the Oracle optimizer to use that index.Why this matters- Restores index-driven performance for Oracle backfills on keyless tables
- No additional configuration required beyond the existing
primaryKeysOverridesetting
Auto-skip primary key constraints when using primaryKeysOverride
When a table has primaryKeysOverride configured, Artie now automatically omits the PRIMARY KEY (...) constraint from destination DDL. Previously, this had to be configured manually, and a separate bug prevented primaryKeysOverride from reaching Transfer for Oracle pipelines entirely.Why this matters- Prevents destination table creation failures when overridden keys include nullable columns
- Fixes Oracle pipelines that rely on unique indexes instead of declared primary key constraints
KMS-managed keys for column encryption
Column encryption previously required a plaintext passphrase in configuration. Customers who store their encryption passphrase in AWS KMS — as required by many security policies — could not use Artie’s column encryption feature at all.Column encryption now supports AWS KMS-managed keys viaencryptionKMSConfig. The previous behavior (plaintext passphrase) continues to work unchanged.Why this matters- Unblocks column encryption for teams with KMS-enforced security policies
- No behavior change for existing plaintext-passphrase configurations
MongoDB snapshot retries on network errors
Transient network failures during a long MongoDB snapshot — connection resets, timeouts, or connection pool errors — would previously abort the entire backfill, requiring a manual restart.MongoDB snapshot retries now cover network-level failures and connection pool cleared errors, not just server-side cursor errors.Why this matters- Eliminates manual restarts caused by transient network blips during large snapshots
- Especially useful for long-running collection backfills over unstable connections
MySQL parallel backfill (integer primary keys)
Backfills are often the longest part of onboarding a new pipeline and a major source of time-to-value delays for large tables.Artie now supports parallel backfills for MySQL tables with integer primary keys. During the initial load, Artie automatically chunks a table into primary-key ranges and backfills those ranges concurrently instead of performing a single-threaded scan.For example, iforders.id ranges from 1 to 200,000,000, Artie can split that range into multiple chunks and backfill them in parallel.Why this matters- Dramatically reduce wall-clock time for large initial loads
- Turn one slow sequential scan into multiple concurrent range reads and writes
- Keep backfill logic simple and deterministic using primary-key ranges
- Enable much faster onboarding for large MySQL tables, especially when replicating from read replicas, without changing schema or writing custom partitioning logic
Faster Postgres reader (2×+ throughput)
Postgres CDC pipelines can fall behind when write volume spikes or during large catch-ups.We optimized Artie’s Postgres reader by improving compression and eliminating several O(N) hot paths in the replication reader. As a result, pipelines can now sustain 2×+ higher CDC throughput before falling behind.Why this matters- Reduce replication lag during peak write load
- Allow large backfills or catch-ups to complete much faster
- Increase pipeline headroom so deployments can stay real-time without oversized infrastructure
MySQL Force Timezone (UTC)
MySQL TIMESTAMP values can shift depending on the session or server timezone, which can create subtle inconsistencies across systems.We added MySQL Force Timezone (UTC) to normalize MySQL TIMESTAMP columns to UTC during replication.For example, iforders.created_at is a MySQL TIMESTAMP, enabling this setting ensures Artie writes it as TIMESTAMP WITH TIME ZONE (UTC), so 2026-03-01 10:00:00 is consistently interpreted as 10:00 UTC across destinations.Why this matters- Eliminates timezone drift across pipelines
- Ensures consistent timestamp semantics across systems
- Makes cross-region pipelines and migrations more reliable
MySQL destination support
Artie now supports MySQL as a destination.You can replicate inserts, updates, and deletes from supported sources directly into MySQL tables, keeping the destination continuously in sync.This enables incremental migrations and operational replication workflows. For example, a team upgrading from MySQL 5.7 to MySQL 8.4 can configure Artie with 5.7 as the source and 8.4 as the destination, allowing Artie to continuously apply changes until the final cutover.Why this matters- Safer MySQL upgrades with incremental cutovers
- Continuous replication into operational MySQL systems
- Enables MySQL-to-MySQL migrations and synchronization workflows
Non-UTF8 encoding support
Artie now supports ingesting data from databases that use non-UTF8 character encodings, including SQL_ASCII (commonly found in legacy MySQL and SQL Server deployments).Artie automatically parses and converts non-UTF8 encoded data during ingestion so it can be safely processed by UTF-8 based destinations and downstream systems.Why this matters- Reduces ingestion failures caused by encoding mismatches
- Improves compatibility with legacy databases
- Enables pipelines from older systems without additional configuration
OpenTofu support
Artie now supports OpenTofu.Teams can define and manage Artie pipelines, sources, and destinations using OpenTofu configuration. Changes can be planned and applied using standard OpenTofu workflows (tofu plan, tofu apply) and versioned alongside the rest of your infrastructure.Why this matters- Manage Artie configuration using Infrastructure-as-Code
- Version pipeline configuration in Git
- Promote changes cleanly across environments (dev → staging → prod)
- Works for teams that have migrated from Terraform to OpenTofu
Apache Iceberg is now supported as a destination in Artie
Iceberg is increasingly used as the table format for lakehouse architectures, but real flexibility depends on how the catalog layer is implemented.Artie previously supported Iceberg through S3 Tables. This release expands support to include Iceberg REST Catalog.Teams can now configure Iceberg as a destination using REST-based catalogs, enabling compatibility with systems such as Databricks Unity Catalog, Snowflake Polaris, Dremio, and other Iceberg-native platforms.Iceberg is now supported as a first-class destination in Artie across both S3-backed and REST-backed catalog configurations.Why this matters- Enables Iceberg deployments across multiple lakehouse platforms
- Supports REST-based catalog interoperability
- Decouples ingestion from platform-specific metadata layers
- Expands architectural flexibility for modern data stacks
OpenTofu support
Artie now supports OpenTofu.Teams can define and manage Artie pipelines, sources, and destinations using OpenTofu configuration. Changes can be planned and applied using standard OpenTofu workflows (tofu plan, tofu apply) and versioned alongside the rest of your infrastructure.Why this matters- Manage Artie configuration using Infrastructure-as-Code
- Version pipeline configuration in Git
- Promote changes cleanly across environments (dev → staging → prod)
- Works for teams that have migrated from Terraform to OpenTofu
Table-Level Monitoring
Pipeline-level monitoring can hide issues in individual tables.When aggregate metrics look healthy, a single critical table can still be degrading unnoticed.Now there is table-level monitoring within a pipeline.Teams can now configure monitors per table, including anomaly detection based on historical behavior and threshold-based alerts (row count, data volume) with customizable evaluation windows.It’s granular visibility without increasing alert noise.Why this matters- Detect issues in critical tables even when pipeline metrics look normal
- Reduce unnecessary alerts across low-impact tables
- Tune monitoring to table-specific ingestion patterns
- Strengthen reliability in high-table-count pipelines
Selective Backfills by Upstream Source
When multiple databases or schemas fan into a single pipeline, backfills can unintentionally reprocess far more data than intended.Previously, triggering a backfill at the table level would re-run that table across every upstream database in the pipeline. In environments with 20 or 30 sources, a change intended for one database could execute across all of them.This update adds selective scoping for table-level backfills in fan-in pipelines.You can now choose exactly which upstream databases to include in a backfill. For schema-level fan-in, you can scope the backfill to specific schemas. Execution is limited to only the selected sources.Destination merge behavior remains unchanged. Only the upstream execution scope is constrained.Why this matters- Prevents unnecessary reprocessing across all fan-in sources
- Reduces blast radius in multi-tenant pipelines
- Speeds up onboarding of new databases
- Improves operational control during remediation
- Avoids unintended warehouse usage during backfills
Non-UTF8 encoding support
Artie now supports ingesting data from databases that use non-UTF8 character encodings, including SQL_ASCII (commonly found in legacy MySQL and SQL Server deployments).Artie automatically parses and converts non-UTF8 encoded data during ingestion so it can be safely processed by UTF-8 based destinations and downstream systems.Why this matters- Reduces ingestion failures caused by encoding mismatches
- Improves compatibility with legacy databases
- Enables pipelines from older systems without additional configuration
Oracle shadow tables for tables without primary keys
Added support for replicating Oracle tables that do not have primary keys.For such tables, Artie creates a corresponding shadow table that mirrors the structure of the original table. Database triggers are configured to propagate insert, update, and delete operations from the source table to the shadow table.The shadow table enables deterministic change tracking, allowing Artie to replicate data from Oracle tables that would otherwise be unsupported due to the absence of a primary key.This expands compatibility with legacy Oracle deployments and improves replication coverage.Configuration: Enabled automatically for Oracle source tables without primary keys.Snowflake Turbo Mode (Dynamic Warehouse Scaling)
Snowflake warehouse sizing is a constant balancing act. Provision for peak load and you overpay most of the time. Provision for average load and ingestion lag builds during spikes.This release introduces dynamic warehouse scaling to remove that tradeoff.Artie can now automatically switch between a configured default warehouse and a higher-capacity warehouse when ingestion lag and workload thresholds are exceeded. Once backlog clears, it switches back.Scaling decisions are evaluated every 10 minutes and validated across consecutive checks to prevent false positives.The result: performance during spikes without permanently oversized compute.Why this matters- Automates a common manual operational task
- Prevents lingering oversized warehouses after traffic spikes
- Maintains ingestion performance during high-demand periods
- Reduces unnecessary Snowflake spend during steady state
- Improves reliability without additional monitoring overhead
Improved Postgres Replication Slot Monitoring
Replication slots are vital to reliable CDC - but they’re easy to forget about until something breaks. When third-party slots go inactive or unbounded WAL grows in the background, it can quietly strain your Postgres instance and jeopardize replication.This release gives Postgres users an early warning system: We’ve expanded our validation job to monitor all replication slots on your Postgres instance. If a third-party slot becomes inactive, is lost, or retains too much WAL, Artie will alert you before it causes trouble.No more surprises. Just clean, proactive safeguards around slot health - regardless of the consumer.Why this matters- Detects inactive or missing replication slots before they affect data syncs
- Prevents unbounded WAL buildup from neglected third-party slots
- Surfaces slot health issues that would otherwise go unnoticed
- Improves database stability when running multiple replication tools
- Gives teams visibility into all replication consumers, not just Artie
Post-Upgrade Volume Anomaly Detection
Upgrades are a critical part of improving infrastructure, but they’re also a common point of failure. Even with thorough tests, subtle issues can sneak through and quietly impact data pipelines.This release introduces an automated guardrail: real-world volume checks that run after each reader image upgrade to catch anything unusual, fast.Whenever a reader is upgraded, Artie now monitors data volumes processed in the 1-hour and 6-hour windows post-upgrade - and compares them to the same periods from the previous day. If something looks suspicious (too little or too much data), we alert the team immediately.It’s an extra layer of safety that catches problems before they break downstream systems.Why this matters- Adds automated verification to a high-risk moment in pipeline lifecycle
- Catches subtle issues that may pass tests but impact real-world throughput
- Prevents silent regressions after reader image upgrades
- Alerts proactively so teams can respond before downstream impact
- Builds trust in Artie’s upgrade process for mission-critical pipelines
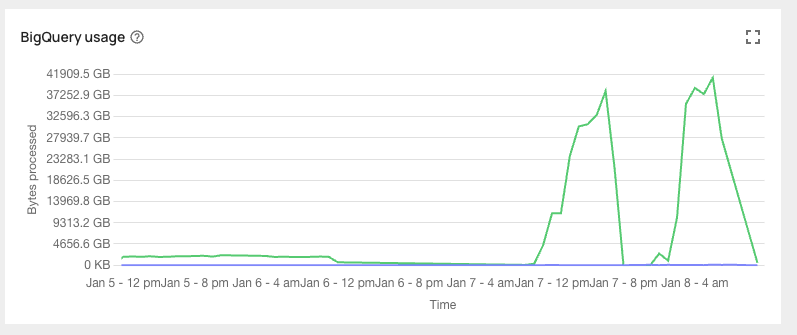
BigQuery Bytes Scanned Visibility
BigQuery’s on-demand pricing can be a black box - and an expensive one. When costs spike, it’s often hard to know why until after the bill arrives.This update brings much-needed visibility: Artie now surfaces bytes scanned directly in the Analytics Portal, so teams can spot cost drivers before they become problems.If you’re using BigQuery with on-demand pricing, you can now see how many bytes each pipeline query scans - right from the Artie UI. This makes it easier to understand which workloads are driving cost, catch regressions early, and tune pipelines for efficiency.It’s one less dashboard to check - and one more way to stay ahead of unexpected spend.Why this matters- Track BigQuery cost drivers alongside Artie pipeline performance
- Catch spikes in bytes scanned before they impact your bill
- Understand usage trends and regressions at a glance
- Optimize pipelines for efficiency without trial-and-error
- Keep data teams and finance aligned with shared visibility
ClickHouse as a Destination
ClickHouse is a powerhouse for real-time analytics - but feeding it fresh data from transactional systems hasn’t been easy. Most teams resort to batch jobs or custom pipelines that quickly become a maintenance burden.With this release, you can now replicate data into ClickHouse from sources like Postgres or MySQL in near real time using Artie. That means fresher dashboards, faster queries, and less glue code to manage.Artie handles the change capture, transformation, and delivery - so you get ClickHouse’s speed without the ingestion headaches.Why this matters- Simplifies real-time ingestion into ClickHouse from OLTP databases
- Enables low-latency dashboards and user-facing analytics without batch delays
- Reduces need for custom pipelines or third-party ingestion tools
- Keeps analytics fresh as source data changes - automatically
- Ideal for teams building analytics products on top of transactional systems
CockroachDB as a Source
CockroachDB is built for global scale and high availability - but getting its data out cleanly and reliably has been a challenge. Most teams had to roll their own pipelines or compromise on freshness and observability.That’s no longer the case. With native CockroachDB support, you can now replicate changes from CockroachDB directly into Snowflake, data lakes, or other destinations using Artie. This unlocks real-time visibility for analytics, ML, and operational systems - all without the need for custom CDC code or fragile replication jobs.Artie handles schema changes, resiliency, and replication edge cases under the hood - so you don’t have to.Why this matters- Turnkey CDC for teams running CockroachDB - no in-house pipelines needed
- Replicate changes to Snowflake, lakes, and other destinations in real time
- Reduce operational complexity while maintaining observability
- Supports globally distributed apps without compromising data sync performance
- Accelerates adoption of CockroachDB for mission-critical use cases
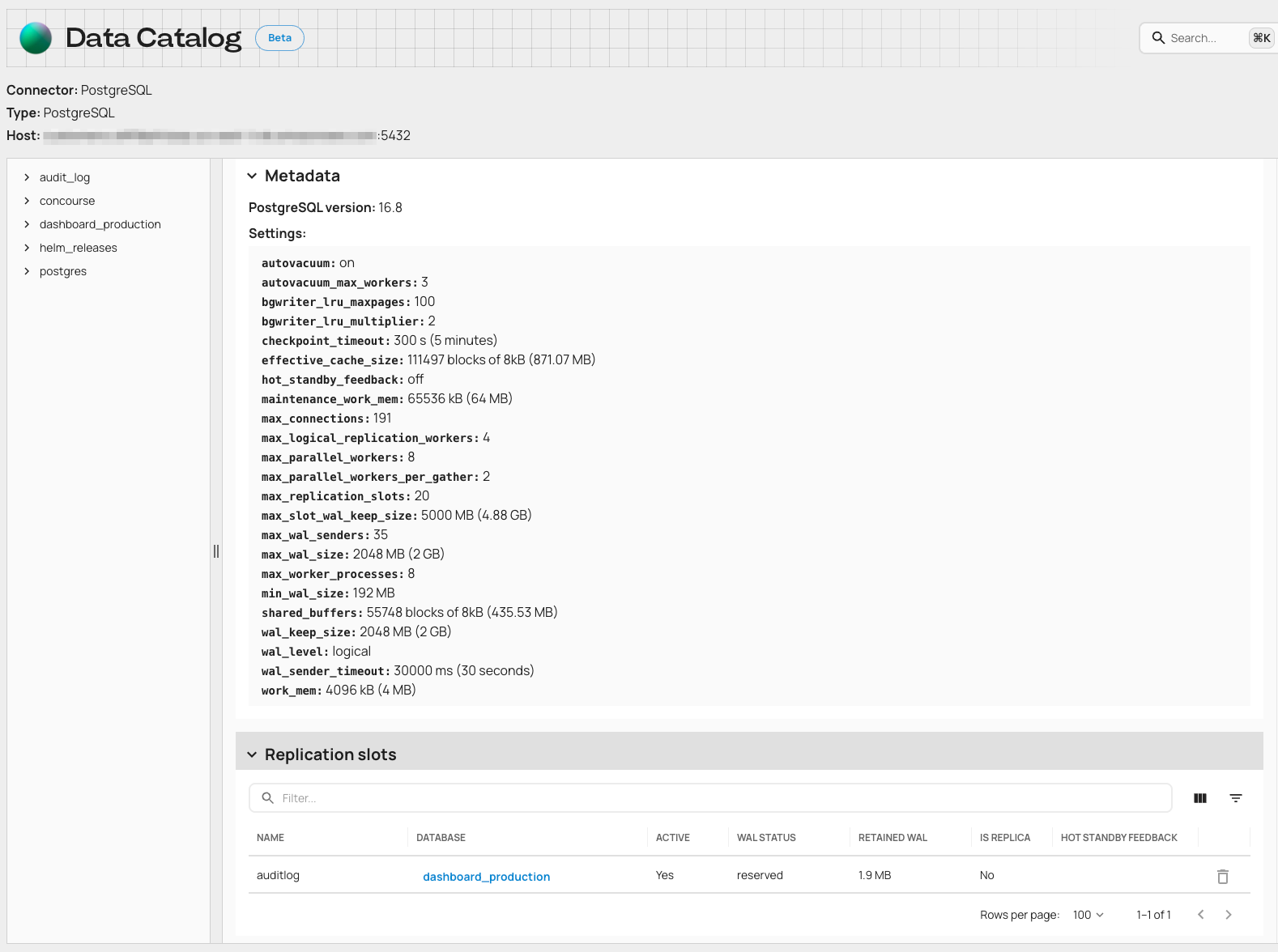
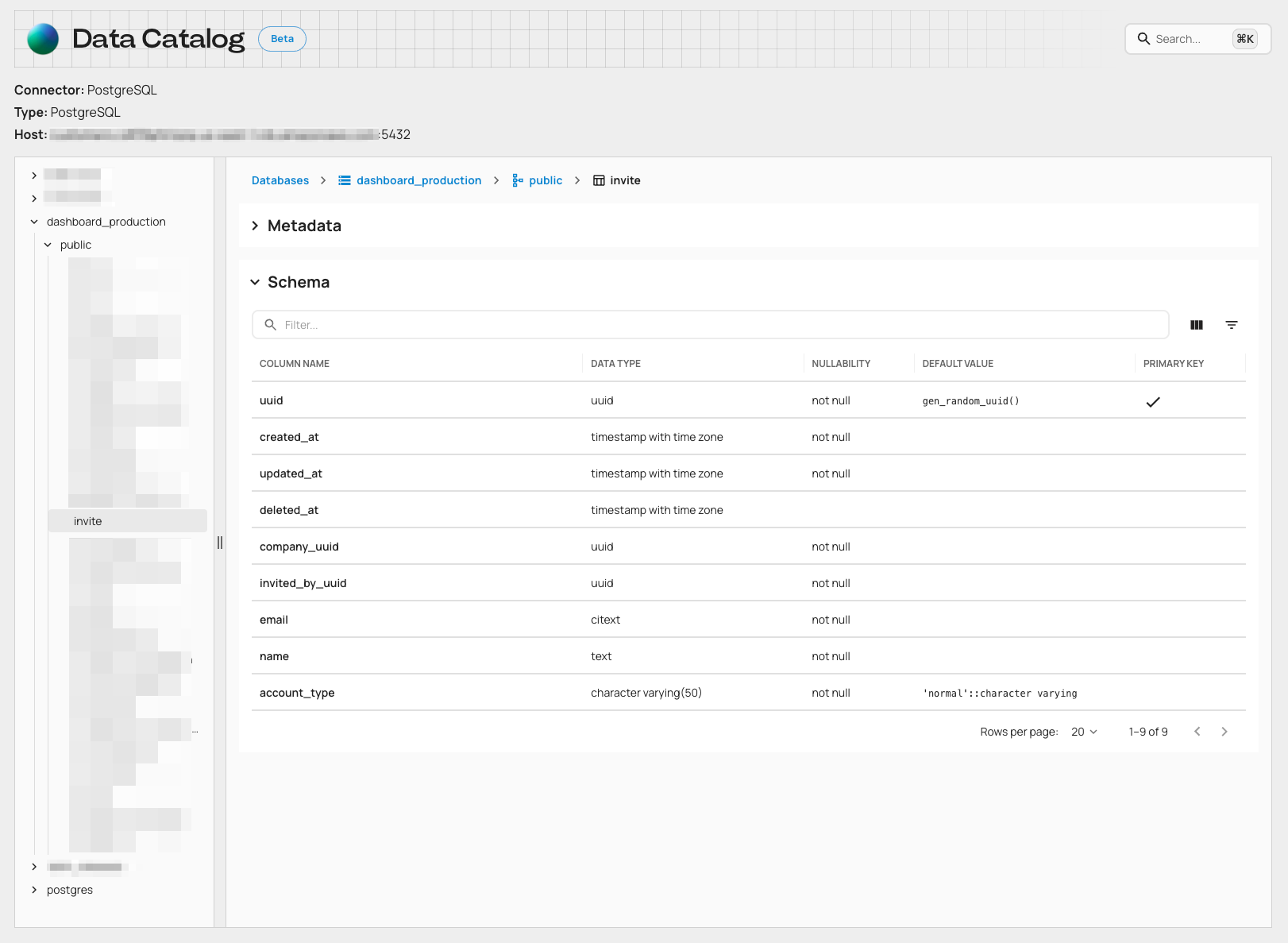
Expanded Data Catalog & Database Insights
When data platforms grow, debugging and visibility gaps grow with them. And while Artie’s Data Catalog already gave teams a centralized look at their databases, there’s more we could surface - especially when platform teams are the ones on call. This release levels up the Catalog, transforming it from a passive browser into a true operational surface.The updated Catalog brings richer metadata across tables and views, clearer schema navigation (including resizable trees), and critical database-level insights like version, settings, and usage context. For Postgres users, you’ll now see replication slot status, publication details, and can even clean up inactive slots - all from the UI.Why this matters- Engineers can browse databases and understand usage without jumping between tools
- Postgres users get instant visibility into replication details - no manual queries needed
- Faster debugging and root cause analysis with actionable metadata and controls
- Reduces reliance on infra engineers for routine database insights
- Makes the Catalog a go-to for both visibility and operations
Iceberg Destinations via Terraform
Until now, Iceberg destinations in Artie could only be configured through the dashboard. That worked well for getting started, but for teams managing their data infrastructure entirely in code, this created a gap: Iceberg pipelines couldn’t live alongside the rest of their Terraform-managed setup.Artie now supports configuring Iceberg destinations through our Terraform provider. You can define Iceberg destinations directly in Terraform, version them in Git, and deploy them the same way you manage the rest of your Artie pipelines and infrastructure. No dashboard-only steps required.For example, a data team can declare an Iceberg destination in Terraform alongside their pipelines, promote it from dev to prod with confidence, and roll out changes automatically as part of their existing infrastructure workflows.Why this matters:- Full infrastructure-as-code support for Iceberg pipelines
- Consistent, reproducible destination configuration across environments
- Easier environment promotion (dev → staging → prod)
- Better alignment with Terraform-first teams and workflows
Azure Data Plane Support
Many enterprise teams standardize on Azure for security, compliance, and networking - and expect their data infrastructure to live there too. Until now, running CDC pipelines often meant processing data outside your Azure boundary, adding friction around approvals, networking, and onboarding. That setup worked, but it wasn’t ideal for organizations with strict cloud and compliance requirements.Artie can now deploy and operate your data plane directly inside your Azure environment as part of our BYOC (Bring Your Own Cloud) model.If your team runs Postgres or SQL Server on Azure, you can provision an Artie data plane inside your own Azure subscription. All CDC processing, buffering, and encryption happen entirely within your network boundary, while Artie continues to manage the control plane and operations.Same managed experience. Full Azure-native control.Why this matters:- Keep CDC processing entirely inside your Azure environment
- Strengthen security and compliance posture
- Reduce cross-cloud data movement
- Accelerate enterprise onboarding with Azure-native networking
History Table Backfill
History tables are most useful when they’re complete. Previously, Artie’s history tables captured changes going forward - which worked well for many workflows, but left teams filling the initial gap with custom scripts or heavy batch jobs when they needed a full baseline. That added setup complexity and made it harder to rely on history tables for downstream incremental processing from day one.Artie can now generate a full historical snapshot for history tables before streaming incremental changes.When you set up a new pipeline, Artie backfills the entire current state of a table into the history table, then seamlessly transitions to streaming ongoing changes. This ensures the history table starts complete, consistent, and ready for production use.Why this matters:- Start history tables with a complete and accurate baseline
- Eliminate custom backfill scripts and batch jobs
- Enable incremental models and continuous processing from day one
- Improve consistency for audits, time-travel queries, and analytics
Google Cloud Storage as a Destination
Teams building on Google Cloud often want real-time data landing directly in GCS - not after a batch job, custom connector, or extra hop through another system. Until now, that meant stitching together ingestion logic and managing yet another moving part in the pipeline. This worked, but it added operational overhead and made real-time lakehouse workflows harder to maintain at scale.Artie can now replicate database changes directly into Google Cloud Storage, writing data in delta Parquet format.You can stream updates from sources like SQL Server or MySQL straight into a GCS bucket, where Artie continuously writes partitioned Parquet files. These files are immediately consumable by downstream systems like BigQuery, Spark, or Databricks - without batch jobs or custom ingestion code.Why this matters:- Build real-time data lakes directly on Google Cloud
- Eliminate custom connectors and batch ingestion jobs
- Improve compatibility with modern GCP analytics tools
- Reduce operational overhead while scaling reliably
Self-Serve PrivateLinks
For teams running secure data pipelines, private connectivity isn’t optional - it’s required. Until now, setting up an AWS PrivateLink with Artie meant coordinating through support, which added friction when standing up new pipelines or environments. That worked, but it slowed down teams who wanted to move fast while still meeting strict security requirements.You can now request and create AWS PrivateLinks directly from the Artie dashboard or via Terraform.When configuring a new pipeline - like SQL Server or Snowflake - you can generate a PrivateLink endpoint with a single click in the UI, or by adding a simple Terraform block to your infrastructure code. Artie handles the rest, keeping the connection private end-to-end.Why this matters:- Create PrivateLinks instantly without involving support
- Keep all data traffic off the public internet
- Fit cleanly into existing Terraform-based workflows
- Speed up pipeline setup for secure environments
Pipeline Change History
As pipelines grow more complex - and more people touch them - it gets harder to answer simple questions: What changed? When? And why did things break? Without a clear record, teams often end up guessing, scrolling through Slack, or retracing steps by hand.Pipeline Change History adds long-overdue visibility into how your pipelines evolve over time, without changing how you manage them today. It shows a complete, time-ordered history of every configuration change made to a pipeline.Any update - adding or removing tables, adjusting flush rules, toggling history mode, or changing settings - is automatically recorded. You can see exactly what changed, when it changed, and who made the change, all in one place.This history is immutable and always available, giving teams a reliable source of truth for pipeline configuration changes.Why this matters:- Quickly pinpoint configuration-related issues during debugging
- Improve collaboration across teams managing shared pipelines
- Eliminate guesswork around “what changed last”
- Maintain an audit trail for compliance and internal reviews
Snowflake Transient Staging Tables
Staging tables are meant to be temporary. But in Snowflake, permanent tables still incur failsafe storage costs - even when time travel is set to zero. For pipelines that constantly create, drop, and recreate staging tables, that overhead quietly adds up.For teams running high-volume CDC pipelines, this meant paying ongoing storage costs for data that only lives for the duration of a single pipeline run. The workflow worked fine - but the cost model wasn’t optimized for how staging data is actually used.Transient tables eliminate both time travel and failsafe storage, making them a better fit for short-lived, ephemeral data. Artie creates transient staging tables at runtime, uses them for the current pipeline execution, and drops them when they’re no longer needed - keeping only the data required to safely apply changes downstream.There’s no change to pipeline behavior, reliability, or correctness. Just a more cost-efficient implementation under the hood.Why this matters:- Lower Snowflake storage costs for ephemeral staging data
- No failsafe charges for tables that don’t need long-term recovery
- Identical pipeline behavior and reliability
- Especially impactful for high-throughput or frequently running pipelines
Skip Backfill for New Tables
When adding a new table to an existing pipeline, a full backfill isn’t always needed. Many teams already have historical data loaded, or they’re incrementally onboarding tables as part of a phased migration. Until now, Artie always kicked off a backfill by default - which worked well for most workflows, but added unnecessary time and compute for cases where history was already in place. This update gives you finer control with a lighter touch.You can now choose to skip the historical backfill when adding a new table. If your warehouse already contains the table’s past data - like a transactions table you loaded earlier - simply selectSkip backfill during deployment. Artie will begin streaming new CDC changes immediately, without performing any historical load.Why this matters:- Avoids unnecessary backfills when history already exists
- Cuts down on compute usage and speeds up table onboarding
- Helps teams moving through partial or staged migrations
- Reduces time to first CDC events for newly added tables
- Gives more control over how tables join existing pipelines
Cross-Database Table Selection for MySQL
Teams running MySQL can split their data across multiple databases - sometimes for tenancy, sometimes for logical separation, sometimes just historical reasons. Until now, capturing from multiple databases meant creating multiple connectors. That setup worked, but it added configuration overhead and made large environments harder to manage. This update simplifies the workflow without changing how existing connectors behave.You can now capture tables from multiple MySQL databases using a single connector. Instead of spinning up separate connectors for sales_db, inventory_db, and analytics_db, you can select tables from all of them under one configuration. Artie handles the routing and CDC capture behind the scenes, so your pipelines stay clean while your coverage expands.Why this matters:- Reduces connector sprawl across MySQL environments
- Cuts down configuration and long-term maintenance
- Makes it easier to scale CDC coverage as databases multiply
- Simplifies monitoring and observability with fewer moving pieces
- Ideal for teams managing sharded, multi-database, or multi-tenant MySQL setups
Per-Table Pause Control
Sometimes you need to make a change to a single table - a migration, a cleanup, a schema tweak - without touching the rest of your pipeline. Previously, pausing replication meant pausing the entire stream, which worked but wasn’t ideal for teams juggling table-level maintenance on busy systems. This update gives you more precise control without disrupting healthy tables.You can now pause replication for an individual table while the rest of the pipeline keeps streaming as usual. If you need to work on a table like orders, you can temporarily pause it, perform your updates, and resume when ready - with zero impact to other tables. Artie continues capturing changes for the paused table in Kafka, ensuring nothing is lost, and automated reminders kick in after two days so paused tables never slip through the cracks.Why this matters:- Gives fine-grained control during table-level maintenance or troubleshooting
- Avoids unnecessary downtime by keeping the rest of the pipeline running
- Captures all changes for the paused table so no updates are missed
- Sends reminders after two days to prevent data loss from Kafka’s 14-day retention window
- Helps maintain CDC continuity even during complex schema work
BigQuery Integer Partition Support
Some BigQuery workloads organize data using integer partitions instead of dates - think customer segments, numeric ranges, or custom “day” encodings. Until now, Artie’s merge logic focused on time-based partitions, which covered most schemas but didn’t fit teams using integers to keep massive tables fast and organized. This update expands that flexibility without changing how existing BigQuery pipelines work.Artie can now write to and merge into tables partitioned by integer columns. Whether you’re partitioning by something like customer_id or a numeric transaction_day, you can select that column as your merge predicate when configuring your table. Artie will handle partition-aware merging behind the scenes, keeping performance high even as tables scale.Why this matters:- Supports a broader range of BigQuery schema patterns
- Improves merge efficiency for large, integer-partitioned tables
- Enables cleaner modeling for teams that don’t use time-based partitions
- Reduces the need to redesign tables just to fit replication workflows
- Aligns with existing BigQuery best practices for performance tuning
Amazon Keyspaces Role Assumption Support
Teams using Amazon Keyspaces often rely on AWS IAM roles to manage access across accounts, environments, and services. Until now, Artie required static credentials for Keyspaces authentication - which worked well for many setups, but wasn’t ideal for teams standardizing on role-based access. This new capability brings Keyspaces authentication in line with how modern AWS environments already operate.You can now configure Artie to authenticate to Amazon Keyspaces using AWS IAM role assumptions rather than storing long-lived access keys. Artie will assume the specified role at runtime and use temporary credentials behind the scenes - keeping your auth flow aligned with AWS security best practices and reducing operational overhead. If you’re already using IAM roles for cross-account or federated access, this fits right in.Why this matters:- Removes the need to store or rotate static AWS credentials
- Aligns with AWS-recommended security patterns and compliance controls
- Simplifies operations in multi-account or federated IAM environments
- Ensures temporary, short-lived credentials are used automatically
- Reduces friction for security-conscious teams adopting Amazon Keyspaces at scale
New Destination: MotherDuck
DuckDB’s columnar engine is fast, lightweight, and increasingly popular for embedded analytics - but moving data from production databases into MotherDuck at scale has meant custom scripts, batch ETL jobs, or settling for stale snapshots. That creates friction between operational systems and the teams trying to run analytics on fresh data.Artie now supports MotherDuck as a native destination. You can stream changes from your production databases directly into MotherDuck - with the same real-time CDC, schema evolution, and reliability you expect from Artie. No custom glue code. No batch windows. Just low-latency replication that keeps your analytics in sync with production.Whether you’re building embedded dashboards, running fast SQL queries over replicated tables, or leveraging MotherDuck’s serverless scale for analytics, Artie handles the hard parts: backfills, schema changes, and incremental merges.Why this matters:- Real-time analytics on MotherDuck without custom replication scripts
- Leverage DuckDB’s blazing-fast columnar engine with live production data
- Automatic schema evolution and backfill handling
- Seamless team data sharing via MotherDuck’s organization-level shares
- Lower cost and complexity compared to traditional warehouse replication
Consolidated Table Change Notifications
Teams managing many pipelines often see duplicate table-change alerts for the same connector or database. That worked fine when the number of pipelines was small, but as environments grow, the noise adds up - and it becomes harder to tell which schema changes actually matter. Consolidated notifications streamline that visibility without changing how existing alerts work; they simply make it easier to spot what’s important.Instead of sending separate table-change alerts for every pipeline tied to the same connector or database, Artie now sends one unified notification. If your MySQL server powers three pipelines, you’ll get a single summary of all detected table updates - not three near-identical alerts. This keeps the signal strong, even as your pipeline footprint expands.Why this matters- Reduces redundant alerts across pipelines using the same connector or database
- Makes schema and table changes easier to review in one place
- Helps data teams focus on meaningful updates, not notification noise
- Ideal for admins and data engineers managing large or multi-team environments
Snowflake External Stage Support
Some teams need more control over where their data lands - and how it gets there. Until now, Artie pipelines wrote to Snowflake using only internal stages, which worked well for most workflows. But for teams with stricter compliance, security, or hybrid cloud policies, internal staging could feel limiting.Artie now supports external stages for Snowflake. You can configure Artie to load delta files into your own storage - like an S3 bucket or Azure Blob - before they’re merged into Snowflake. This gives your data team full control over staging, retention, and permissions, while still keeping Artie’s fully managed replication experience.Why this matters- Keep full visibility and ownership of staged data before merge
- Align with internal compliance and audit requirements
- Manage your own storage, permissions, and lifecycle policies
- Enable hybrid or BYOC (Bring Your Own Cloud) setups without losing ease of use
- Maintain the same performance and reliability - with more flexibility
High-Volume Usage Monitor
For data teams running massive pipelines, staying ahead of data surges is mission-critical. A sudden spike in rows processed can mean surprise bills, downstream overloads, or missed SLAs. Until now, tracking this required piecing together dashboards and manual checks - useful, but reactive.You can now create monitors that automatically alert you when data volume crosses a defined threshold or when usage patterns deviate from normal. Whether it’s 500M rows in a day or a 3× spike in pipeline throughput, you’ll get ahead of potential cost overruns and operational slowdowns - before they hit.Why this matters:- Detect anomalies early and prevent unexpected vendor costs
- Maintain transparency and control over high-volume pipelines
- Proactively safeguard SLAs and downstream systems
- Improve cost predictability for finance and operations
- Reduce manual monitoring with automated, intelligent alerts
Environments
Running multiple pipelines across dev, staging, and production can get messy fast. Without clear isolation, a simple misconfiguration - like a staging job writing to production - can turn into a costly mistake. Until now, Artie pipelines existed in a shared global context. That worked fine for smaller teams, but for complex setups, it made managing multiple deployment stages harder than it needed to be.You can now create and manage pipelines within distinct environments - like “staging,” “dev,” or “production.” Each environment has its own scoped resources, connectors, and destinations, ensuring full isolation between stages.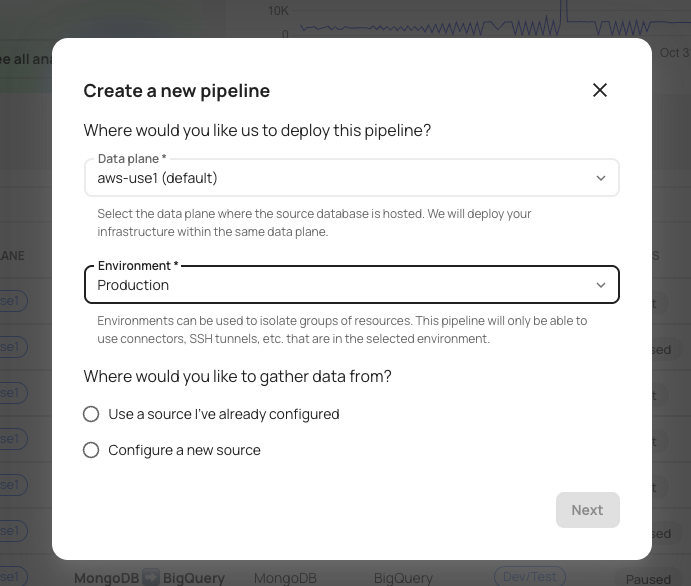
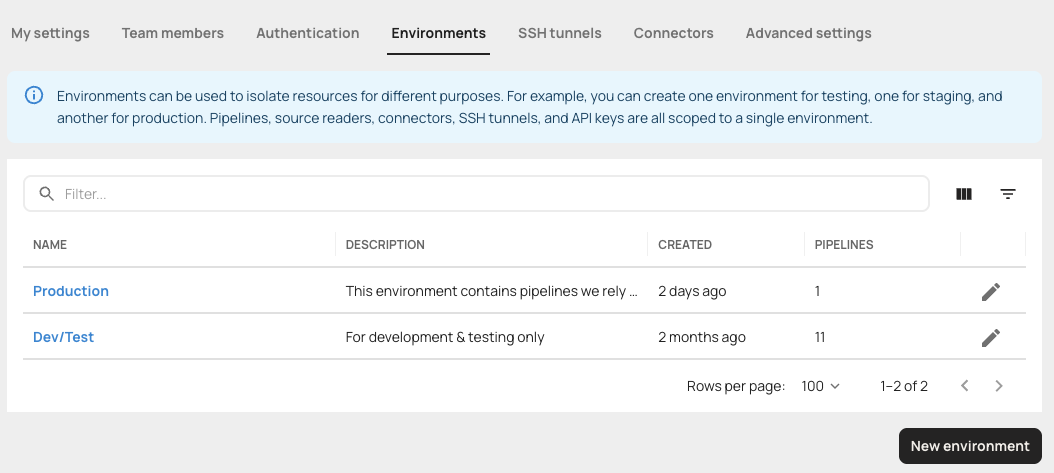
- Prevents cross-environment mistakes that can corrupt production data
- Makes testing safer and deployments more predictable
- Improves governance and access control by isolating resources
- Enables clean promotion of pipelines from staging to production
- Builds confidence for teams managing large-scale, multi-stage data flows
Improved Pipeline Overview
When you’re managing hundreds (or thousands) of tables across multiple pipelines, finding the one table that’s lagging shouldn’t feel like a scavenger hunt. Until now, visibility across pipelines meant jumping between tabs and manually piecing things together.The new Pipeline Overview provides a unified list of all replicated tables per pipeline - complete with instant search, filters, and live status metadata. You can now quickly slice by schema, filter by status, or pinpoint a specific table, all from one clean interface. It’s faster, clearer, and built for scale.Why this matters:- One consolidated view of every table in your pipeline
- Instant search and filtering for faster troubleshooting
- Live status updates make it easy to spot and prioritize issues
- Simplifies triage and impact analysis for large-scale replication setups
- Big quality-of-life boost for teams managing many pipelines
.png?fit=max&auto=format&n=6_dnk1lYLlEUapG9&q=85&s=55690b3eb4fd5804b13f9f9f3af262e0 "image (1).png")
SQL Server Change Tracking
Not every SQL Server environment allows full CDC or log access - especially in managed or restricted setups. For many teams, that’s meant choosing between limited replication options or overburdening DBAs just to enable streaming.Artie now supports Change Tracking (CT) as a replication method, alongside CDC and T-SQL log reading. CT captures primary keys and version numbers for changed rows directly from SQL Server, enabling low-latency, incremental syncs without requiring elevated permissions or direct log access.You can enable CT on selected tables, and Artie will automatically detect and replicate changes in near real time - maintaining the same reliability and consistency you expect from our streaming architecture.Why this matters:- Lightweight replication with minimal database overhead
- Works in restricted SQL Server environments where CDC/log access isn’t possible
- Reduces dependency on DBAs and complex permissions
- Maintains low-latency, reliable syncs across managed and hosted deployments
- Expands deployment flexibility for diverse SQL Server environments
Native PagerDuty Paging
When a pipeline stalls at 2 a.m., the last thing you need is another integration breaking. Until now, connecting Artie alerts to PagerDuty required custom webhooks or scripts - brittle setups that quietly fail when you need them most.You can now connect Artie monitors directly to PagerDuty. No glue code. No webhook maintenance. When a pipeline alert fires - say latency spikes past five minutes or data volume drops below expected thresholds - Artie automatically triggers an incident in PagerDuty for the correct service, complete with context like pipeline name, destination, and error type.Why this matters:- Native integration with your existing PagerDuty schedules and escalation policies
- Faster triage with alerts that include full pipeline context
- Lower MTTR by unifying alerting and incident management
- Zero-maintenance setup - no webhooks or scripts to babysit
- Fewer missed alerts and more reliable on-call coverage
Supporting Amazon Keyspaces (Cassandra) as a Source
Cassandra workloads are built for massive scale and availability - but getting that data into your analytics or AI systems in real time has always been a pain. Teams have had to choose between building custom pipelines or living with stale data. That stops now.Artie can now stream data directly from Amazon Keyspaces into your destinations - no glue code, no custom connectors. Backfill and stream changes from wide-column Cassandra tables into Snowflake, Redshift, or Databricks, with full handling of partition keys, clustering columns, and all native Cassandra data types. The result: low-latency replication that just works, delivering sub-minute end-to-end freshness.Why this matters:- Real-time analytics and AI on Cassandra data - without manual pipelines
- Unlocks operational data trapped in wide-column stores
- Full schema mapping and type handling for Cassandra’s flexible model
- Consistent, predictable performance at scale
- Lower operational risk and engineering overhead
Displaying Redshift Views & DDL in Catalog
When debugging or reviewing data pipelines, context matters. Until now, seeing the full picture of your Redshift environment often meant hopping between Artie and Redshift to check view definitions or table schemas. That context switching slows teams down and introduces room for error.You can now see Redshift views alongside tables-complete with their full CREATE VIEW and CREATE TABLE definitions-right inside Artie’s data catalog. The catalog reflects the authoritative Redshift schema, so you get an instant, accurate snapshot of how data is structured without leaving Artie.Why this matters:- No more switching between Artie and Redshift just to check definitions
- Faster debugging and impact analysis with full view context in one place
- Better governance - everyone sees the same, authoritative schema version
- Fewer mistakes when modifying or extending pipelines
- Improved collaboration between engineers and analysts reviewing data models
Soft Partitioning
High-volume ingestion often strains data warehouses - especially when append-heavy streams like events or transactions flood a single target table. Over time, that leads to slower merges, higher costs, and unpredictable performance. Artie’s new Soft Partitioning feature changes that.Soft Partitioning introduces logical, time-based partitioning at Artie’s ingestion layer. Artie automatically routes incoming rows into partitioned tables (likeuser_events_2025_08, user_events_2025_09, …) while maintaining a unified view (user_events) that queries seamlessly across all partitions. This works independently of your destination’s native partitioning - so you get consistent, predictable performance whether you’re writing to Snowflake, Redshift, or Databricks.Why this matters:- Predictable write performance for high-throughput, append-only streams
- Reduced merge and update costs by limiting heavy work to recent time slices
- Full control over partition lifecycle - prune, compact, or roll up by time range
- Unified view across partitions for simple, cross-partition querying
- Consistent behavior across all destinations, without custom tuning
Displaying Unreadable Schemas in Postgres
Until now, our Postgres dashboard only showed schemas that your service account could read. For most teams sticking with the default schema, that was fine - but for anyone using custom schemas, it could feel like parts of your database had simply disappeared.Your Postgres dashboard will now surface all schemas, even if Artie doesn’t have read access. When a schema is unreadable, we’ll explicitly mark it as such. Instead of leaving you guessing why only a subset showed up, you now get full visibility into what’s there - and what’s out of reach.Why this matters:- Clearer visibility: see all schemas in your database, not just the readable ones
- Less confusion: no more wondering why certain schemas aren’t appearing
- Faster troubleshooting: instantly know whether access permissions are the reason a schema isn’t syncing
- More control: make informed decisions on which schemas to grant access to
View Only Role
Until now, access to the dashboard was limited to admin and edit roles. That worked fine for smaller teams - but for larger orgs, it meant you either gave stakeholders too much power or kept them out entirely.With the new view only role, you can invite stakeholders into the dashboard with read-only access. They’ll be able to see pipelines, monitor sync status, and stay informed - but won’t be able to change settings or modify configurations. This strikes the right balance: visibility without risk.Why this matters:- Invite stakeholders who only need visibility into pipeline health and status
- Reduce the risk of accidental changes to critical configurations
- Scale collaboration across larger teams without adding overhead
- Keep admins and engineers focused on managing pipelines, while others stay informed
Schema Exclusion Rules for Postgres Fan-In
When fanning in data from Postgres, things can get tricky if two schemas on the same server contain tables with the same name - but different formats. For example, tenant-specific schemas should be unified, while other schemas with overlapping table names should stay separate. Without guardrails, this creates collisions and inconsistent data downstream.You can now use regular expressions to exclude specific schemas from automatic fan-in. To make setup easier, Artie previews which schemas match (and don’t match) your rule before replication starts - giving you full visibility and control.Why this matters:- Designed for customers managing complex fan-in scenarios
- Prevents incorrect unification of tables that share names but differ in structure
- Reduces downstream data errors and inconsistencies
- Eliminates manual filtering and fragile workarounds
- Provides transparency by previewing schema matches before syncing
Postgres: Publication Support Via Partition Root
Partitioned tables in Postgres can be tricky to manage. Until now, Artie required users to define a regex pattern to capture all partition names - which worked fine, but made replication fragile and error-prone for complex partitioning strategies.With Postgres’ built-in publish_via_partition_root option, we’re making things much simpler. Instead of juggling regex patterns, you can now rely on Postgres to publish changes directly through the root table.If you’re using partitioned tables (for example, events_2025_09, events_default, or any custom partition scheme), Artie can now replicate them as if they were a single root table. No regex, no manual upkeep - just treat your partitioned tables like regular ones and let Artie handle the rest.Why this matters:- Less fragile: no need to maintain regex rules across changing partitions
- Simpler setup: treat partitioned tables like any other Postgres table
- Fewer errors: Postgres ensures changes flow through the root, reducing replication pitfalls
- More flexibility: works with custom partitioning schemes, not just time-based ones
Backfill by Schema for Fanned-In Tables
When tables are fanned into a single destination table from multiple schemas, backfills used to be all-or-nothing. That worked fine for most teams - but sometimes you only need a slice. Maybe one schema changed while the others stayed the same. Until now, you’d have to backfill everything, even if just one schema needed attention.You can now target specific schemas when backfilling a fanned-in table. For example, if a destination table is built from schemas A, B, and C, but only schema C requires a refresh, you can backfill just schema C without touching A or B. This gives you more control, avoids unnecessary data churn, and keeps things lean.Why this matters:- More precise backfills - update only what you need
- Faster recovery from schema-specific changes
- Lower compute and warehouse costs by skipping redundant data
- Less operational risk when dealing with large fan-in pipelines
Full Source Table Name Support
When data is sharded across multiple upstream tables, primary keys are often only unique within each table-not across all of them. Until now, that meant fanning data into a single destination table wasn’t possible without risking collisions.You can now include the complete source table name ({{database}}.{{schema}}.{{table}}) as a column in your replication stream. This provides additional metadata about where each row originated. You can also choose to make this new column part of the primary key - giving you a surrogate key that ensures uniqueness across shards.Why this matters:- Replicate sharded datasets into a single destination table without key conflicts
- Preserve visibility into the exact origin of each record
- Eliminate the need for complex workarounds or manual deduplication
- Unlock new fan-in use cases for teams consolidating data from many sources
Pending Status for Pipelines
Sometimes, when you make a change to a pipeline, it can take a few minutes before everything is deployed to our data plane. Until now, the UI didn’t give you much feedback - leaving some customers wondering if their update had gone through.Pipeline actions are now displayed with a pending state while they’re being applied. Instead of guessing whether your deployment worked, you’ll see right away when a pipeline is in progress - and when it’s fully live.Why this matters:- Removes confusion when pipeline changes take 2–5 minutes to deploy
- Provides clear visibility into the status of your updates
- Helps teams trust what they’re seeing in the dashboard
- Reduces unnecessary support questions like “I clicked update, but nothing happened”
Consolidated Pipeline Change Notifications
Managing dozens of pipelines shouldn’t mean managing dozens of alerts. Until now, schema changes or pipeline issues like credential rotations triggered one email per pipeline. That worked fine when you had just a handful of pipelines, but for teams running 30, 50, or even 80+ pipelines, inboxes quickly got overloaded.Instead of sending a separate email for each pipeline event, Artie now rolls them up into a single alert. You’ll still see exactly which pipelines are affected - whether it’s a schema change, a connection timeout, or a credential update - but without the avalanche of duplicate emails.Why this matters:- Cut down on alert fatigue - fewer emails, clearer signal
- Immediate visibility into which pipelines are affected, all in one place
- Scales with your environment, whether you manage 3 pipelines or 80
- Keeps alerts actionable - you know what happened, where, and when
New Data Type Support for Postgres
Postgres is powerful because of its flexibility, but until now, many advanced data types weren’t supported in replication tools. That meant teams using features like multiranges or custom composite types had to rework schemas or maintain brittle workarounds - slowing them down.With this update, Artie removes that limitation. For teams building production-critical systems on Postgres, you can now replicate complex data types with the same reliability as standard ones.We’ve added support for:- TSTZMULTIRANGE (multirange): Added in Postgres 14, this lets you store multiple non-overlapping time intervals in one column - perfect for tracking availability windows without conflicts.
- Custom enums: Define your own set of valid string values, like a controlled list of statuses or product sizes, and replicate them reliably.
- Custom composite (tuple) types: Create structured types that combine multiple fields into one, such as storing an address (city, state, street) in a single column.
- Supports advanced Postgres use cases without schema redesign
- Eliminates brittle workarounds when using complex data types
- Keeps replication consistent across real-world customer schemas
- Opens the door for more application-specific modeling in Postgres
Static Columns
Sometimes, teams need more than just the raw data replicated into their warehouse. They also need a way to enrich it with business context - like tags, labels, or metadata that help downstream teams stay organized. Until now, this meant managing that metadata separately, which could lead to extra steps and inconsistencies.You can now add static columns to an existing pipeline. These columns will automatically appear in the destination table alongside your replicated data.For example, a team might use static columns to tag records with region (EU or US), environment (prod or staging), or a unique system identifier. Instead of tracking this separately, the metadata now flows directly with your replicated data - no extra plumbing required.Why this matters:- Keep your downstream data organized with consistent metadata
- Add business context (like region or environment) directly into destination tables
- Reduce manual tagging and cleanup steps after replication
- Enable richer analytics and easier filtering across datasets
Source Metadata Columns
When you’re consolidating data from multiple sources, it’s not always enough to just move the rows - you also need to know where they came from. Without that context, compliance checks get harder, debugging slows down, and downstream apps lose critical signals. Artie makes it simple to retain that lineage.You can now enable source metadata columns in Advanced Settings. When turned on, Artie appends an extra column to replicated tables containing details like transaction ID, log sequence number, schema, table, and database name.For example:- A fintech consolidating dozens of sharded MySQL databases into one Snowflake table can track exactly which shard each row came from.
- A healthcare company can capture source database and table information for HIPAA audit logs.
- A payments team can tie replicated rows back to original transaction IDs for fraud analysis.
- Traceability: See exactly where each row originated, even across shards.
- Auditability: Support compliance and security workflows with source-side context.
- Debugging: Isolate discrepancies quickly by filtering on schema/table metadata.
- Flexibility: Build custom fraud detection, routing, or monitoring logic using metadata.
Unifying Tables Across Schemas
For teams managing sharded or micro-sharded databases, downstream complexity multiplies fast. Each shard or schema produces its own copy of every table. That means instead of M tables, you end up with N × M tables in your warehouse (where N = number of shards/schemas, M = number of tables). Analysts are stuck stitching them back together, engineers write endless union queries, and operations teams lose the clean, consolidated view they need.You can now unify tables across schemas directly in replication. Instead of landing one table per schema, Artie automatically merges them into a single, consolidated destination table.Take an e-commerce platform sharding customers across 50+ schemas: instead of 50 separate users tables, you now get one unified users table downstream. Or a payments company splitting transactions across micro-shards: all those rows flow neatly into one transactions table in Snowflake. With Artie’s fan-in option, the number of downstream tables is simplified back to M, and schema evolution is handled automatically.Why this matters:- Simplified data model: query one table instead of wrangling dozens, with schema evolution managed for you.
- No duplication: eliminate manual unions or stitching scripts in the warehouse.
- Consistent structure: unified naming across shards improves data quality and usability.
- Effortless scaling: add new shards upstream, and they automatically merge downstream.
Microsoft Teams Notifications
Artie has long supported notifications via email and Slack. That worked fine, but for teams who live in Microsoft Teams, having alerts show up directly in their workspace is a big quality-of-life improvement.You can now receive pipeline alerts and notifications directly in Microsoft Teams. Whether it’s replication status, schema changes, or operational alerts, everything flows into the same workspace your team already uses. This builds on our existing notification support (email and Slack), giving you another way to stay connected to your pipelines.Docs 👉 How to enable Teams notificationsLarge JSON Support for Redshift
JSON payloads are everywhere - but when they get large, most tools fall short. Many platforms land JSON into VARCHAR(MAX), which caps out at ~65k characters. For teams working with rich event logs, nested API responses, or anything more complex, that limit means truncated payloads and lost data.When Artie encounters large JSON payloads, we now land them as the SUPER data type in Amazon Redshift. SUPER supports documents up to 16MB in size, preserving the full payload without truncation. That means you can capture, query, and transform large, complex JSON documents in Redshift without compromise.Why this matters:- Preserve entire JSON payloads instead of losing data to truncation
- Unlock the full power of Redshift’s semi-structured query capabilities with SUPER
- Handle large event logs, nested API responses, and other big JSON columns with ease
- Avoid manual workarounds or post-processing to recover lost information
Specifying Snowflake Roles
Some Snowflake service accounts are like Swiss Army knives - they have multiple roles, each with its own permissions and environment. Until now, Artie simply authenticated with the service account’s default role. That worked for straightforward setups, but for teams running multiple environments (like staging, pre-prod, and prod) from a single service account, it meant juggling credentials or sticking to a one-size-fits-all role.You can now tell Artie exactly which Snowflake role to use when authenticating with a service account.- Simplifies credential management - no more creating and rotating multiple service accounts for different environments
- Keeps environments isolated - staging stays staging, prod stays prod, even with the same account
- Supports better security practices - roles can be scoped to the exact permissions needed
- Reduces operational overhead - fewer accounts to configure, monitor, and maintain
Sub-Second Pipeline Deployment
When you’re rolling out dozens (or hundreds) of pipelines at once, every second counts. The old 3–5 second deploy time per pipeline worked fine for smaller updates - but for large-scale rollouts, those seconds piled up fast, sometimes even hitting Terraform’s execution timeouts. That meant splitting deployments into batches, manually tracking progress, and adding friction to what should’ve been a quick rollout.Pipeline deployments now complete in under 0.5 seconds each. Whether you’re launching 10 pipelines or 100+, they’ll deploy in a fraction of the time - keeping Terraform applies well within limits and eliminating the need for batching or manual retries.Example: One customer managing 150+ pipelines can now spin up 40 new pipelines in under 20 seconds, with their largest rollouts finishing in minutes.Why this matters:- Keeps Terraform applies under execution limits - no more timeout failures
- Eliminates the need for splitting deployments into smaller batches
- Cuts large-scale rollout time to seconds/minutes
- Frees engineers from manual progress tracking and retries
Flush Metrics Now Available in Analytics
For teams replicating high-volume data into destinations like Snowflake, BigQuery, or Postgres, setting the right flush rules is key to balancing freshness, cost, and performance. But without visibility, tuning those rules can feel like guesswork.Flush rules let you control when data gets written from Artie’s streaming buffer to your destination - based on time intervals, row counts, or byte thresholds. With Flush Metrics, you now get a clear view into how those rules are performing.Take a healthtech team syncing MySQL to BigQuery: they’ve configured a 60-second or 1MB flush rule. Now, they can see exactly how often data flushes, what triggered it, and how long it took - helping them optimize for cost and latency without guessing.
- Tune pipelines with data - not guesswork
- Validate whether your flush rules are hitting SLAs
- Optimize for warehouse costs by spotting over-frequent writes
- Troubleshoot delays and fine-tune performance in seconds
New Destination: Postgres
Not every use case belongs in a warehouse. Teams often need to move transactional data into Postgres to power real-time APIs, partner-facing systems, or operational dashboards - without the complexity of Snowflake or the fragility of DIY CDC scripts.Until now, Artie’s destinations focused on analytics platforms. But operational systems matter too - and we’re making sure you’re covered.You can now stream changes from your source databases directly into Postgres - just like any other Artie pipeline. It’s fully managed, fault-tolerant, and handles schema changes and backfills automatically.Some teams are already using it to power internal tools by syncing MySQL to Postgres - skipping the warehouse entirely. Others are using Postgres-to-Postgres replication to isolate production workloads or build live replicas for disaster recovery.Same reliability. New destination.Why this matters:- Power real-time APIs and dashboards without a warehouse
- Eliminate fragile CDC scripts with a fully managed solution
- Sync across Postgres instances to isolate workloads or support disaster recovery
- Handle schema changes and backfills automatically - no maintenance required
Self-Serve DynamoDB Backfills
Backfills are a critical step in onboarding new pipelines - especially when you’re working with historical data in DynamoDB. Until now, Artie handled that part for you, kicking off a table export behind the scenes. That worked fine - unless something broke. If your AWS role didn’t have the right permissions or something else went sideways, users were left guessing.Now, that guesswork is gone.When setting up a DynamoDB pipeline, you’ll now see a guided flow in the UI that helps you kick off a backfill. You can export the table directly from your AWS account - or select an existing export if you’ve already started one manually.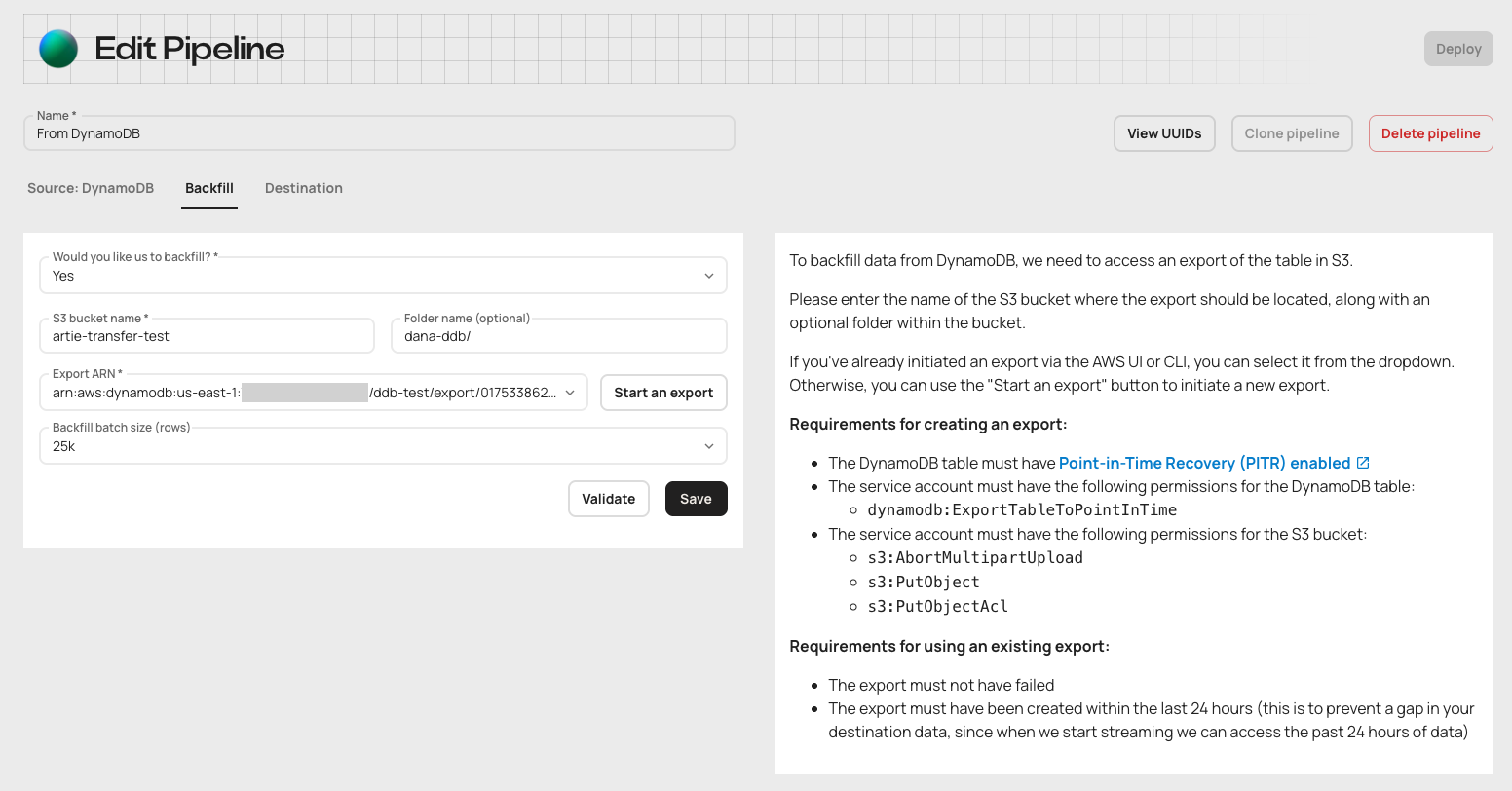
- DynamoDB backfills are now fully transparent and user-controlled
- Errors (like missing permissions) are surfaced immediately for faster fixes
- Reuse recent exports - no need to start from scratch
- Smoother, more reliable onboarding for new DynamoDB pipelines
Parallel Segmented Backfills for Postgres
CTID-based backfills are fast and efficient - especially for large, append-only Postgres tables. They scan directly by physical row location, often outperforming logical queries in stable datasets.But CTIDs come with tradeoffs: they’re slow to initialize for large tables, fragile in dynamic tables where rows update or move, and they can time out in environments with aggressive statement_timeout settings.For teams working with massive, constantly changing Postgres tables, these limitations can stall backfill progress or create reliability risks.Parallel Segmented Backfills offer an alternative path. Instead of relying on CTID, Artie slices tables into logical row segments based on integer primary keys - then parallelizes the work across those chunks.The result: similar performance to CTID backfills, but with stronger guarantees in dynamic environments.We recently helped a customer backfill 8 billion rows in an actively updated Postgres table. CTID-based scans kept timing out and drifting. With Parallel Segmented Backfill, we split the workload across logical row ranges and completed the job - no timeouts, no skipped rows, no guesswork.Why this matters:- Resilient to updates and vacuuming - row movement doesn’t break backfills
- Offers CTID-level performance with better reliability under load
- Avoids statement_timeout failures in large or busy tables
- Makes backfill behavior predictable and tunable
Improved DDL Support for Cell-Based Architectures
In environments with multiple isolated databases - like production, staging, and dev - schema drift is a persistent risk. Columns added in one cell might not appear in another unless there’s active data flowing through. That means teams looking at the “same” table in Snowflake could be seeing different structures, leading to confusion, bugs, and broken dashboards.This became especially painful for teams whose QA and Dev environments receive little to no traffic. With our previous behavior, tables wouldn’t update unless a row changed - leaving environments out of sync.Artie now supports schema alignment across environments.We’ve introduced a new opt-in job that automatically checks and syncs table schemas across environments - even when there are no row changes. If a new column shows up in production, it’ll get added to dev and staging too, so all environments stay aligned.This feature ensures you get consistent schemas, no matter how much (or little) traffic a database gets.Why this matters- Guarantees column consistency across environments (prod, staging, dev)
- Eliminates silent schema drift in low-traffic databases
- Supports cell-based and single-tenant architectures out of the box
- Reduces debugging time and improves trust in test environments
External Stage Support for Snowflake
Some teams need more control over where their data goes - and how it gets there. Maybe it’s for compliance. Maybe audit. Or maybe they just don’t want Snowflake touching their data until the very last step.By default, Artie loads delta files into Snowflake using internal staging before merging them into the target table. That worked fine for most workflows - but some teams need an extra layer of control over how data flows through their environment.You can configure Artie to write delta files to a Snowflake external stage - like your own S3 bucket - and we’ll read from there when applying changes to your target table.This gives organizations - like federal agencies using Snowflake Gov Cloud - the ability to use an external stage in their own environment, keeping data fully under their control for things like internal review, validation, or security scanning before deciding to merge into Snowflake.Same fully managed sync. Just with the files landing in your environment first.Why this matters✅ You keep full visibility into what’s being staged before it’s merged✅ You can retain delta files for auditing or reprocessing - entirely on your terms
✅ You get tighter control over when data crosses trust boundariesThere’s no impact on performance. No extra cost. Just more flexibility, when you need it.Want to turn this on? Let us know - we’ll help you get set up.
Column Control: Include, Exclude, Hash
Not every column needs to make it to your warehouse.Some fields are sensitive. Some are noisy. Some just don’t belong anywhere near analytics.
Now, you can decide exactly what gets replicated - and what doesn’t - with Artie’s expanded column-level controls.Here’s what’s now possible, per column:
✅ Inclusion - define an allowlist. Only replicate what you explicitly approve; otherwise, ignore
🚫 Exclusion - let most of the table through, but block the columns you don’t want downstream
🔐 Hashing - keep the structure, mask the value. Track fields like user IDs, without exposing data
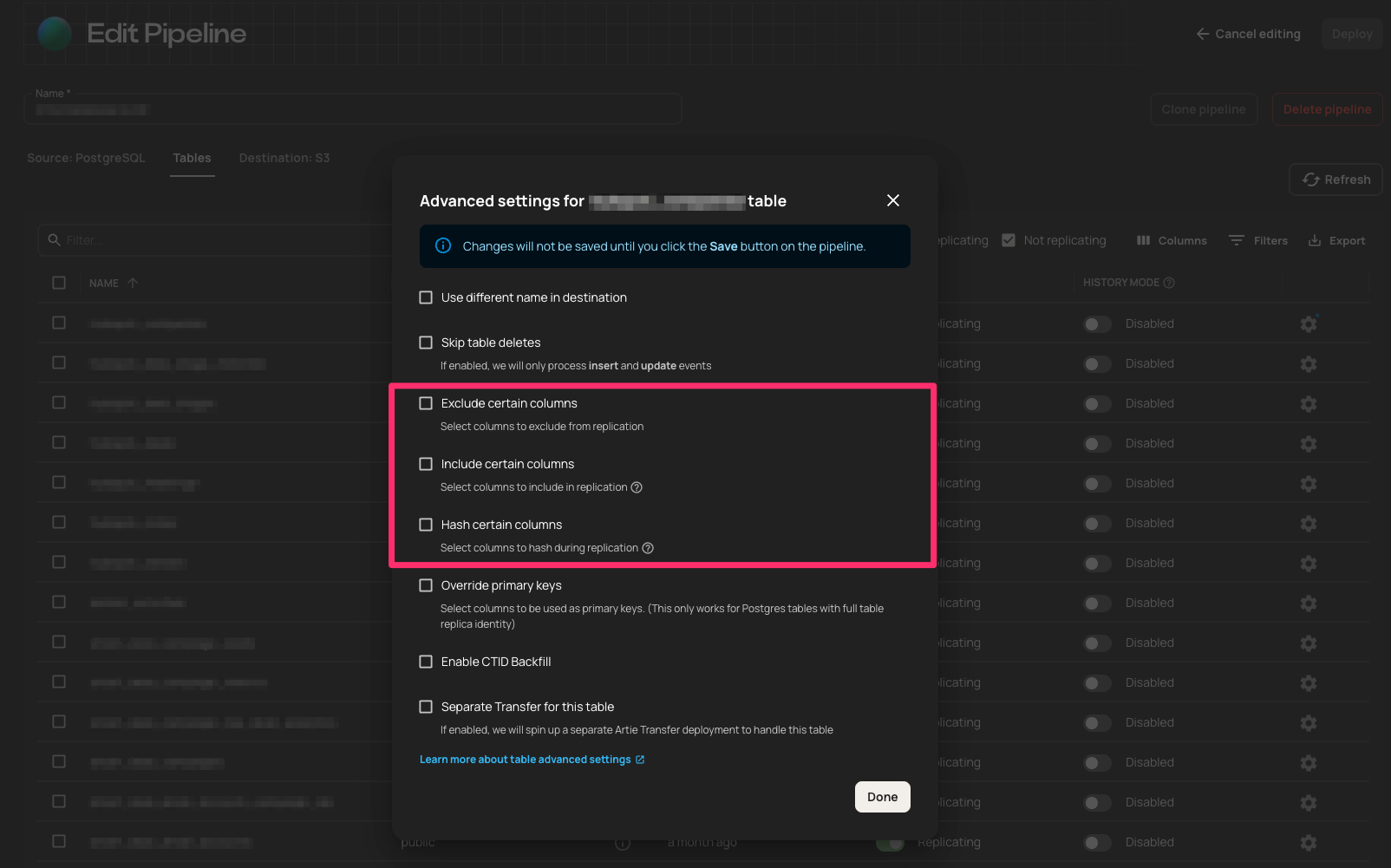
Why this matters:
This isn’t just a cleanup job. It’s control over what leaves prod.InclusionSometimes, it’s not about removing sensitive fields - it’s about only sending the ones you trust. Inclusion rules flip the default: instead of replicating everything and hoping exclusions or hashes catch the risky stuff, you define exactly what gets through - and block the rest.What this means:- Safer by default - no surprises when new columns show up
- Compliance-friendly - ideal for PII and financial data
- Cleaner data - only the fields analytics and ML teams actually need
Exclusion rules let you drop what doesn’t belong - without touching your schema.Use it when:
- You’re skipping internal metadata, debug fields, or legacy junk
- You want to trim without breaking things
- You’re migrating slowly and need a guardrail, not a wall
Hashing keeps them in your pipeline without exposing what’s inside.Reach for hashing when:
- You want to track user behavior across systems without exposing identity
- You’re debugging and need to confirm values match across systems - without logging sensitive data
- You’re sharing a warehouse and want to prevent exposing raw PII to teams that don’t need it
- You only need to know whether or not a value has changed
Column-level rules are set at the source. This guide explains where they belong and why.
CDC for Tables Without Primary Keys
Some tables are weird. No primary key (PK), maybe just a unique index or some composite hack someone added in 2017. Until now, those were off-limits for replication.You can now override PK requirements by specifying a unique index - including composite indexes. Artie will respect the exact column order to ensure optimal performance.Why index-based PK overrides matter:Not every table has a clean PK. Some use unique indexes or composite keys that aren’t formally declared as PKs. Until now, these tables were difficult (or impossible) to replicate. This change addresses one of the most common blockers for CDC at scale.What’s changed:- PK override: Define row identity with a unique index
- Use composite keys - even if unofficial or unenforced
- Preserve the exact index column order – it affects how changes are captured and impacts query performance during replication (e.g.,
email,account_id,created_at)
- Your table lacks a formal PK, but has a unique constraint or index
- You rely on composite keys to identify rows
- You’re dealing with legacy systems or data models that weren’t built with CDC in mind
Backfill Tuning: Picking the Right Batch Size
You can now control how many rows Artie processes at a time during backfills. The default is now 25,000 rows per chunk (up from 5,000), but you can tune this based on performance vs. load tradeoffs.Why backfill batch size matters:Backfills aren’t one-size-fits-all. Some teams want speed. Others are sensitive to database load and tiptoeing around a production DB at 2am. Until now, everyone got the same batch size of 5,000 rows per chunk. Now you can tune backfills to match your style:- The default is 25,000 rows - we benchmarked a bunch of sizes. 25,000 rows won out. So that’s our new default
- You have control - adjust the batch size to fit your environment
- Speed up backfills: Larger chunks = fewer queries, can improve throughput, but overly large chunks can backfire. It’s about finding balance.
- Reduce DB load: Smaller chunks = faster queries, lower impact on source
Read Once and Write to Multiple Destinations
You can now sync data from a single database to multiple destinations - all from the same connector.Why this matters:- Reduce load on production databases by avoiding duplicate reads and minimizing replication slot overhead
- Ability to fan out to multiple tools - e.g., write to both Snowflake and Redshift
- Ability to support diverse use cases in parallel - analytics, ML, real-time alerting
- Operate across multiple data platforms
- Serve many internal teams with different tools
- Need to scale data infrastructure without increasing operational burden
Iceberg Support Using S3 Tables
This launch adds something big: support for Apache Iceberg using S3 Tables.Artie customers can now:- Stream high-volume datasets into Iceberg-backed tables stored on S3
- Use S3 Tables’ fully managed catalog, compaction, and snapshot management
- Query efficiently with Spark SQL (via EMR + Apache Livy) without wrestling with cluster glue
-
Get up to 3x faster query performance thanks to automatic background compaction
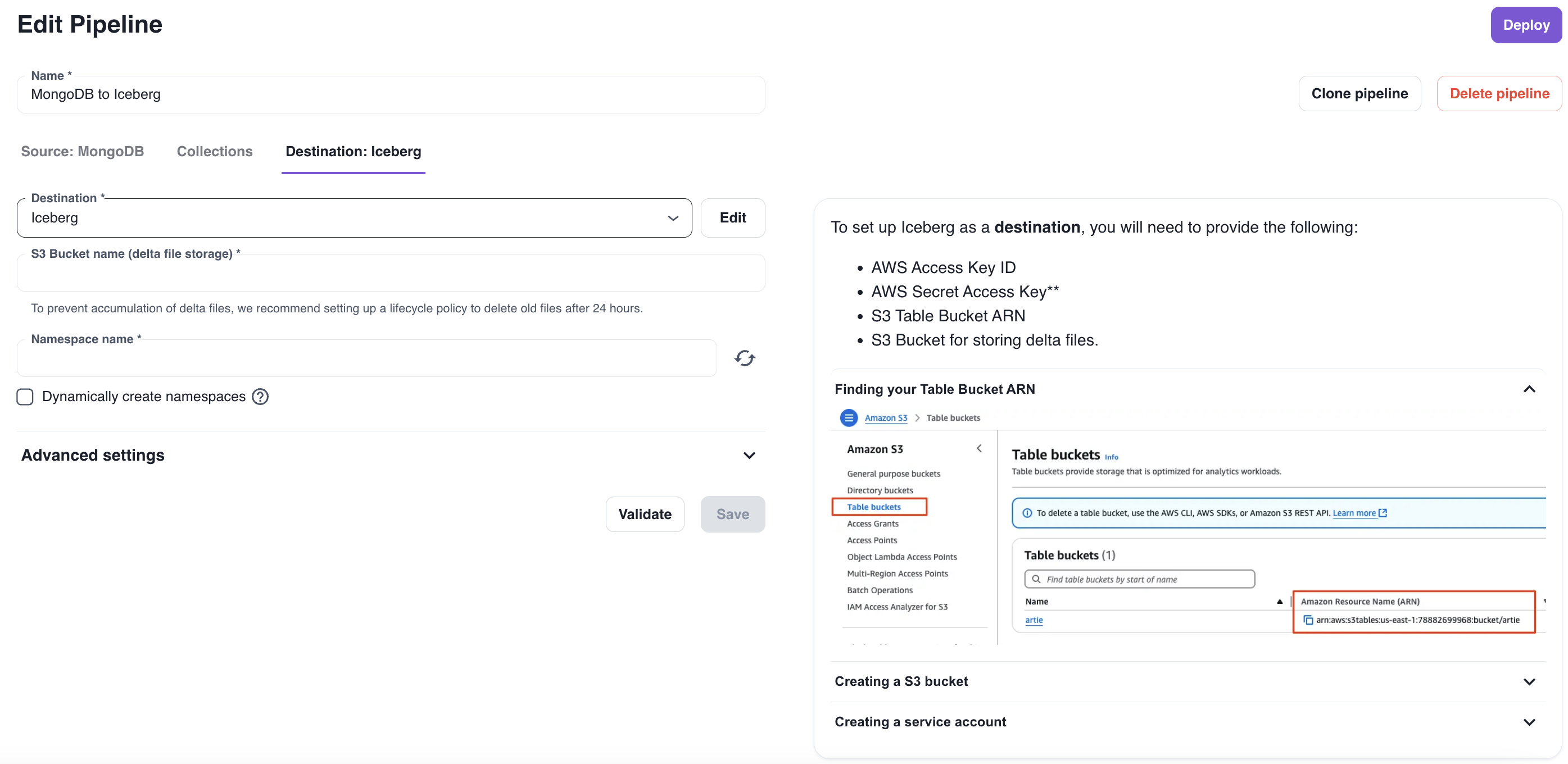
S3 Iceberg destination (Beta)
S3 Iceberg is now available in beta! This new destination uses AWS’s recently released S3 Tables support, allowing you to replicate directly into Apache Iceberg tables backed by S3. It’s a big unlock for teams building modern lakehouse architectures on open standards.Column Inclusion Rules
You can now define an explicit allowlist of columns to replicate - ideal for PII or other sensitive data. This expands our column-level controls alongside column exclusion and hashing. Only the fields you specify get replicated. Everything else stays out.Autopilot for New Tables
Stop manually hunting for new tables in your source DB. Autopilot finds and syncs them for you - zero config required. Turn it on via:Deployment → Destination Settings → Advanced Settings → “Auto-replicate new tables”