

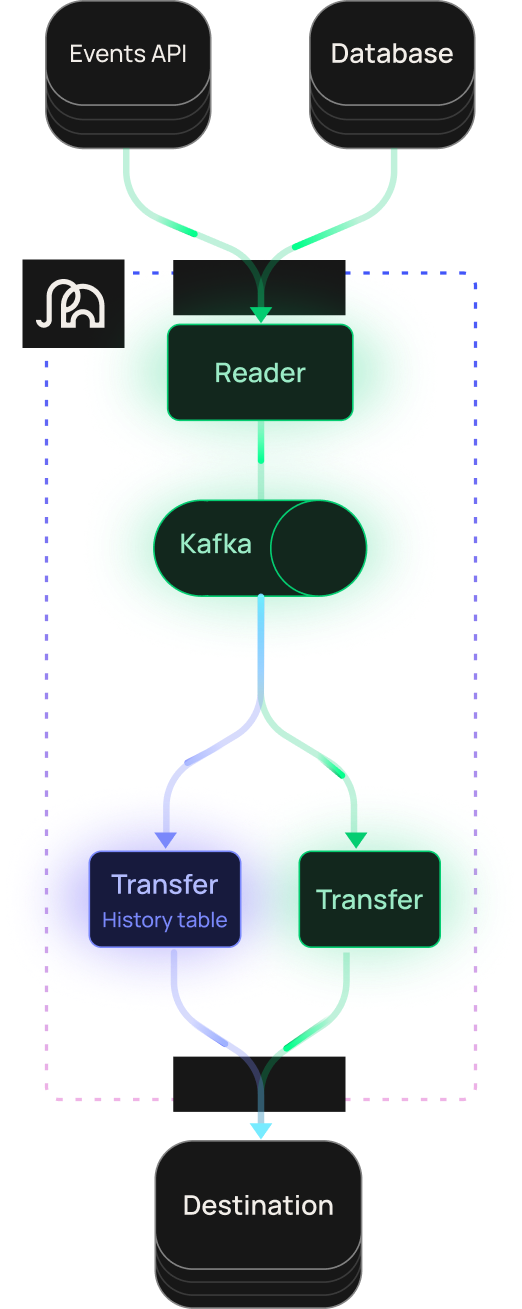
Stream database changes via CDC or ingest events via API in real-time. Everything you’d expect from a system your team spent two years building — except you didn’t have to.



Column adds, drops, and type changes are detected and applied automatically. No pipeline restarts, no manual DDL.

1:1 view of what the table looks like in your destination. DML and DDL fully replicated over.

Track every version of every row over time. Full audit trail in your destination.

Every row lands exactly once. No duplicates, no data loss, even during failures or restarts.

Backfill historical data without impacting your streaming pipeline or your source database.

Pipeline health, throughput, latency, and error tracking in a built-in dashboard. Datadog integration available.
.png)

Connect your Postgres database, select your tables, and point to Snowflake. Artie handles the backfill and starts streaming changes in real time. No Kafka, no Debezium, no infrastructure to provision. Your first pipeline can be live in under 5 minutes.
AI agents and ML models are only as good as the data behind them. Batch pipelines mean your features, embeddings, and context are hours or days stale — leading to hallucinations, stale recommendations, and incorrect predictions. Artie streams changes to your warehouse or lake continuously, so your AI and ML workloads always operate on current data.
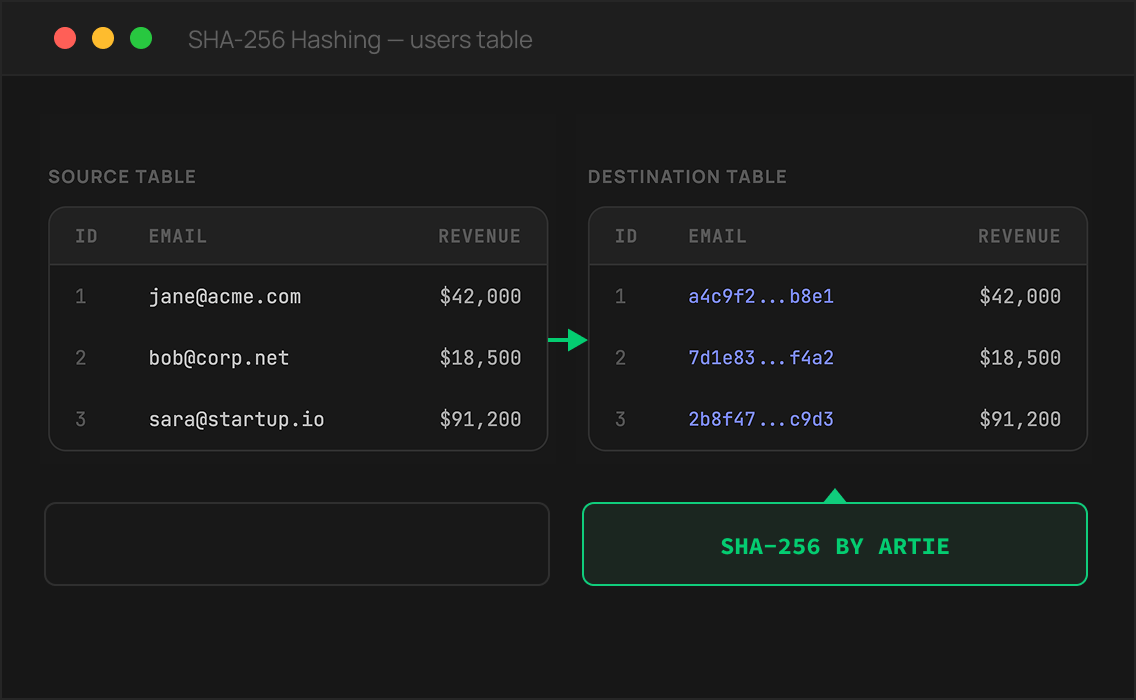
Define which columns to include, exclude, encrypt, or hash — Artie enforces the rules in-flight so sensitive data never lands in the destination unprotected. No post-processing, no separate masking tools, no gaps in coverage.
.png)
Deploy Artie within your own cloud account for full network isolation and compliance control. Data never leaves your VPC — no third-party data transit, no residency concerns. Built for teams with SOC 2, HIPAA, or strict data sovereignty requirements.
Contact SalesReplicate from hundreds of single-tenant databases into one unified schema — without building or maintaining custom ETL. Artie maps each source to the same destination tables automatically, handles schema changes across all sources, and keeps everything in sync in real time.
.png)
.png)
Replicate append-heavy time series data and partition destination tables by time range with soft partitioning — without restructuring your source. Keeps large datasets fast to query and cheap to store, with no manual table management as data grows.









.svg)









.png) 220 Sansome Street, San Francisco, CA 94104
220 Sansome Street, San Francisco, CA 94104




